
規模の大きなプログラムを作る時
ファイル分割
ここまで紹介してきたプログラムは、どれも一つの.cファイルに記述されていました。しかし、実際に用いられる実用的なプログラムは、より大規模になり、一つのファイルには収まりません。実際、ソフトウェア開発の現場には多くのプログラマーが協力してプログラムを作っているのがほとんどです。
そういった場合、必要になってくるのが、ファイル分割です。C言語に限らず、実用的なソフトウェアのプログラムは、複数のファイルに分割されています。分割の仕方は、そのプログラムの機能などによって様々です。
ヘッダファイルとソースファイル
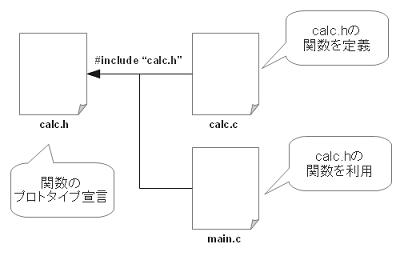
すでの述べたとおり、cには、".h"(ヘッダファイル)と、".c"ファイル(ソースファイル)があります。通常、大きなプログラムは、多数の関数から成っています。そのため、それらのファイルは、規模に応じて複数に分割されることになりますが、通常、ファイルが分割されれば、他のファイルにある関数を呼び出すことが出来なくなります。
そこで、ヘッダファイルに、.cファイルに記述されているファイルの内容を記述しておき、それを読み込むことにより、.cファイルに記述されている関数を利用することが出来るようになります。 実は、このヘッダファイル、プロトタイプ宣言が記述されているファイルなのです。
ファイル分割の実際
サンプルプログラム
では、実際のプログラムでファイル分割を試してみましょう。まずは、関数のところで説明した、list6-3を使ってみましょう。
list6-3:main.c(再掲)
#include <stdio.h>
// 関数avgのプロトタイプ宣言
double avg(double,double);
void main(){
double d1,d2,d3;
double a = 1.2,b = 3.4,c = 2.7;
// 同じ計算が3回(関数を呼び出して計算)
d1 = avg(a,b);
d2 = avg(4.1,5.7);
d3 = avg(c,2.8);
printf("d1 = %f,d2 = %f,d3 = %f¥n",d1,d2,d3);
}
// 平均値を求める関数
double avg(double l,double m){
// 引数l,mの平均値を求め、rに代入する。
double r = (l + m) / 2.0;
return r;
}
このプログラムは、一つの関数から成り立つプログラムです。これをファイル分割にすると、以下のようになります。
list7-1①:calc.h#ifndef _CALC_H_ #define _CALC_H_ // 関数avgのプロトタイプ宣言 double avg(double,double); #endif // _CALC_H_
#include "calc.h"
// 平均値を求める関数
double avg(double l,double m){
// 引数l,mの平均値を求め、rに代入する。
double r = (l + m) / 2.0;
return r;
}
#include <stdio.h>
#include "calc.h"
void main(){
double d1,d2,d3;
double a = 1.2,b = 3.4,c = 2.7;
// 同じ計算が3回(関数を呼び出して計算)
d1 = avg(a,b);
d2 = avg(4.1,5.7);
d3 = avg(c,2.8);
printf("d1 = %f,d2 = %f,d3 = %f¥n",d1,d2,d3);
}
ファイル分割の仕組み
では、list7-1を用いて、ファイル分割の基本について説明してみましょう。まずlist7-1①の、ヘッダファイルcalc.hをみてみましょう。一般に、ヘッダファイルの書式は以下のようになります。
基本的なヘッダファイルの書式#define _(大文字で記述したファイル名)_H_
プロトタイプ宣言;
プロトタイプ宣言;
:
#endif // _(大文字で記述したファイル名)_H_
まず、冒頭に出ている#ifndef、#define、#endifは、マクロと言い、C言語そのものの文法とは無関係ですが、コンパイラに指令を与えるものです。 詳細はここでは省略しますが、これにより、二重インクルードを防いでいます。(図7-1)
| (1) |  |
|
|---|---|---|
| (2) |  |
|
| (3) |  |
|
二重インクルードの防止
では、二重インクルードとはなんでしょう?普通ヘッダファイルは、複数のファイルで参照されます。(図7-1)list7-1でも、calc.c、calc.hでインクルードされます。そのため、1回目は良いのですが、2回目のインクルードでこの間で定義されているプロトタイプ宣言が二回定義されることになり、コンパイルエラーになります。それを回避するために行っているのがこれです。
このとき、#ifndef~#endifマクロで、二重インクルードの防止がなされていなければ、関数などが二重に定義されてしまいエラーになりますが、これではさむことにより、一度定義されたものは二度定義されることは無いのでエラーになりません。
#defineにヘッダファイルの名前に由来したキーワードを用いるのは、絶対にそうでなくてはならないという文法的規約ではありませんが、 この方法が大変わかりやすいため、一般的に用いられている方法です。
 |
ヘッダファイルのインクルード
プロトタイプ宣言は、後に定義する.cファイルで定義する関数のプロトタイプ宣言です。list7-1の例では、関数が一つですが、使用する関数の数だけ定義することが可能です。
さらに、main.cとcalc.cでインクルードすると、このヘッダファイルをインクルードするとき、以下のような書式になります。
作成したインクルードファイルのインクルードの仕方list7-1では、calc.hというヘッダファイルを作ったので、#include "calc.h"と記述します。では、この記述と#include <stdio.h>とどう違うのでしょう?
通常、この例のように、自分で作成した関数のヘッダファイルを読み込むには、"(ダブルクオーテーション)で囲み、stdio.hのような、C言語でもともと用意されているようなものの場合、<と、>に囲まれています。
#includeの使い分け
この厳密な違いは、通常.hファイルに対し、その関数を記述した部分が、.cファイルにソースコードとして書かれている場合は、.hファイルの読み込みは、ダブルクオーテーションで 行います。それに対し、関数の定義の部分が、ライブラリファイル(.lib)など、すでにコンパイルされているものに関しては、<と、>でヘッダファイルを読み込むのです。(図7-3)
 |
通常stdio.hは、標準ライブラリと呼ばれるものの一つで、関数の定義に関してはコンパイル済みです。そのため、ヘッダファイルをインクルードする際には、<と、>を用いるのです。 この他にも、なお、自分で作成した関数をライブラリ化して、後から読み込む場合も、やはり<と、>を用います。
複数のヘッダファイルへの分割
サンプルプログラム
では、次に分割するファイルを少し複雑にし、互いに依存関係のある複数のヘッダファイルに分割する場合を考えてみましょう。まずは、以下のサンプルを見てください。
list7-2:main.c
#include <stdio.h>
// 計算の答え(グローバル変数)
int ans = 0;
void add(int,int);
void sub(int,int);
void showAnswer();
void main(){
int a = 2,b = 3;
printf("%d + %d = ",a,b);
add(a,b);
showAnswer();
printf("%d - %d = ",a,b);
sub(a,b);
showAnswer();
}
void add(int a,int b){
ans = a + b;
}
void sub(int a,int b){
ans = a - b;
}
void showAnswer(){
printf("%d¥n",ans);
}
2 - 3 = -1
このプログラムは見ても判る通り、単純な加算・減算を行うプログラムです。少し変わっているところといえば、その結果が、ansというグローバル変数に入っているところでしょう。
ここから、このプログラムをファイル分割してみます。その際、機能に応じて、計算部分をcalc.h/.cというファイルに、結果表示部分をshowResult.h/.cというファイルにそれぞれ分割してみることにします。
複数のヘッダファイル・ソースファイルへの分割
list7-1を実際にファイル分割したものは、以下のようになります。
list7-3①:main.c
#include <stdio.h>
#include "calc.h"
#include "showResult.h"
void main(){
int a = 2,b = 3;
printf("%d + %d = ",a,b);
add(a,b);
showAnswer();
printf("%d - %d = ",a,b);
sub(a,b);
showAnswer();
}
#ifndef _CALC_H_ #define _CALC_H_ void add(int,int); void sub(int,int); #endif // _CALC_H_
#ifndef _SHOW_RESULT_H_ #define _SHOW_RESULT_H_ void showAnswer(); #endif // _SHOW_RESULT_H_
#include "calc.h"
int ans;
void add(int a,int b){
ans = a + b;
}
void sub(int a,int b){
ans = a - b;
}
#include "showResult.h"
#include <stdio.h>
extern int ans;
void showAnswer(){
printf("%d¥n",ans);
}
グローバル変数の扱い
ヘッダファイルが、calc.h、showResult.hの2つに別れ、それぞれのヘッダファイルに対応する実装が、calc.c、並びにshowResult.cに記述されているのがわかると思います。
ただ、問題は、グローバル変数ansの対応方法です。すでに述べたように、グローバル変数は、プログラム全体で利用できる変数です(6日目参照)。しかし、この例のように、プログラムが複数に分割された場合、宣言されているファイル以外の場所では、グローバル変数は使えなくなってしまいます。
extern修飾子
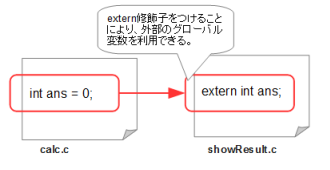
この変数は、calc.c、showResult.cの両方で使用するのですが、定義はどちらか一箇所にしか出来ません。このようなとき、活躍するのが、extern(エクスターン)修飾子です。
extern修飾子の使用例externは、英語で「外に」を意味を持つ言葉です。つまり、この例では、「int ans」という定義が、この宣言が書かれているほかのファイルにあることを意味します。 実際、見てみると、calc.cに、「int ans」があることがわかります。
つまり、この宣言を用いると、その宣言が用いられるファイルの外側にある定義、つまり、この例だとcalc.cの中のint ansを用いることになるのです。 「extern int ans」という記述がある部分では、この値を用いることになります。つまり、cac.cの中のadd()およびsub()関数で用いられているansと 、showResult()関数の中で用いられているansは、同じものをさしているのです。つまり、異なるソースファイルの中で、共通のグローバル変数を利用しているということになるのです。(図7-4)
 |
より高度のファイル分割
ここで取り上げたファイル分割は、あくまでも初歩のものです。enumが入ったり、データの隠ぺいが必要な場合など、より高度なファイル分割については、応用編第7日目を参考にしてください。
Cコンパイラの仕組み
コンパイルの仕組み
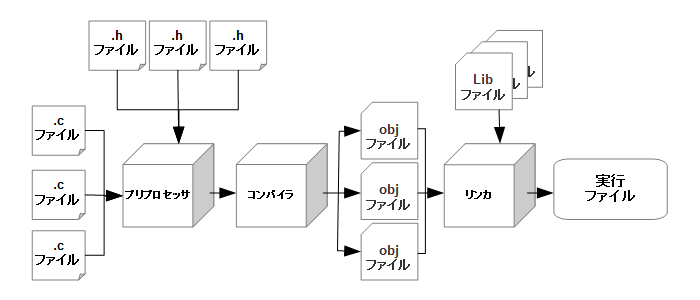
では最後に、いままで内容を踏まえて、こういった複数に分割されたヘッダファイル・ソースファイルがどのようにしてマシン語に変換されているのかを理解するため、C言語のコンパイラの仕組みをより詳しく説明しておくことにしましょう。まずは、以下の図を見て下さい。(図7-5)
 |
すでに述べた通り(0日目参照)、C言語のプログラムは、コンパイラによって、最後にはマシン語に変換されて、実行されます。変換されたマシン語は、実行ファイルと呼ばれるファイルに記録されます。
コンパイラの3つのプロセス
つまり、Cコンパイラの仕事は、ソースファイルを最終的に実行ファイルに変換することなのです。この処理には大きく分けて、以下の3つのプロセスがあります。
①プリプロセッサ
プリプロセッサは、ソースコードに一定の規則に従って処理を加えます。これによって、各ソースファイルおよび #includeや、#defineといったような、マクロの処理をするのが段階です。一般に、こういった命令をディレクティブと呼びます。この段階で行われるのは、いわばコンパイルの前処理といったところです。
②コンパイラ
プリプロセッサで処理されたコードを機械語に翻訳するのが、コンパイラの役割です。ただ、ここでは実行可能な形でのファイル ではなく、obj(オブジェ)ファイルもしくは、オブジェクトコードと呼ばれるファイルが形成されます。
オブジェクトファイルは、機械語に変換されたコードの断片の集まりであり、これらが最終的につながる(リンク)されることにより、 実行可能なファイルになります。
③リンカ
最終的に、コンパイラで作成された複数のオブジェクトファイルを一つにまとめて、実行ファイルを作るのがこの段階です。ただ、 Cの標準ライブラリなど、Cのソースコードだけでは足りない部分は、lib(ライブラリ)ファイルとして、ここで追加されます。 これらが統合されて、最終的な実行ファイルになります。
実行ファイルとビルド
OSがウィンドウズの場合、実行ファイルには、「exe」という拡張子がついています。このファイルを、そのつづりから「エグゼファイル」などと 呼んだりします。
以上がCコンパイラの仕組みです。このように、プリプロセッサから、リンカまでの処理を通して、一般に、ビルドという言い方をします。 VisualStudioや、Eclipseなどの統合開発環境(とうごうかいはつかんきょう)は、ソースコードの入力から、ビルド、更には実行までを一手に引き受けてくれる プログラムなのです。
最後に
まとめ
以上で、C言語の基本は終了です。ただ、残念ながら、これまでの知識だけでは、十分なプログラムがかけるとは言えません。しかし、ここにはC言語を学ぶ初心者が最初に抑えておくべき基本事項が網羅されています。あとは、この応用に過ぎません。ですので、これまでの内容をしっかりと学習し、より高いレベルにチャレンジしてみてください。
より高度な学習のために
より高いレベルにチャレンジしたい学習者のために、発展編が用意されています。ここまでの内容を理解した方は、ぜひチャレンジしてみてください。
| → 発展編第1日目へ |
|---|
また、これまでの知識をベースにさらなる専門知識を身につけるために、さまざまな書籍を利用して学習してみるとよいでしょう。
| → C言語の学習に役立つ書籍 |
|---|
練習問題 : 問題7.
 |  |  |



